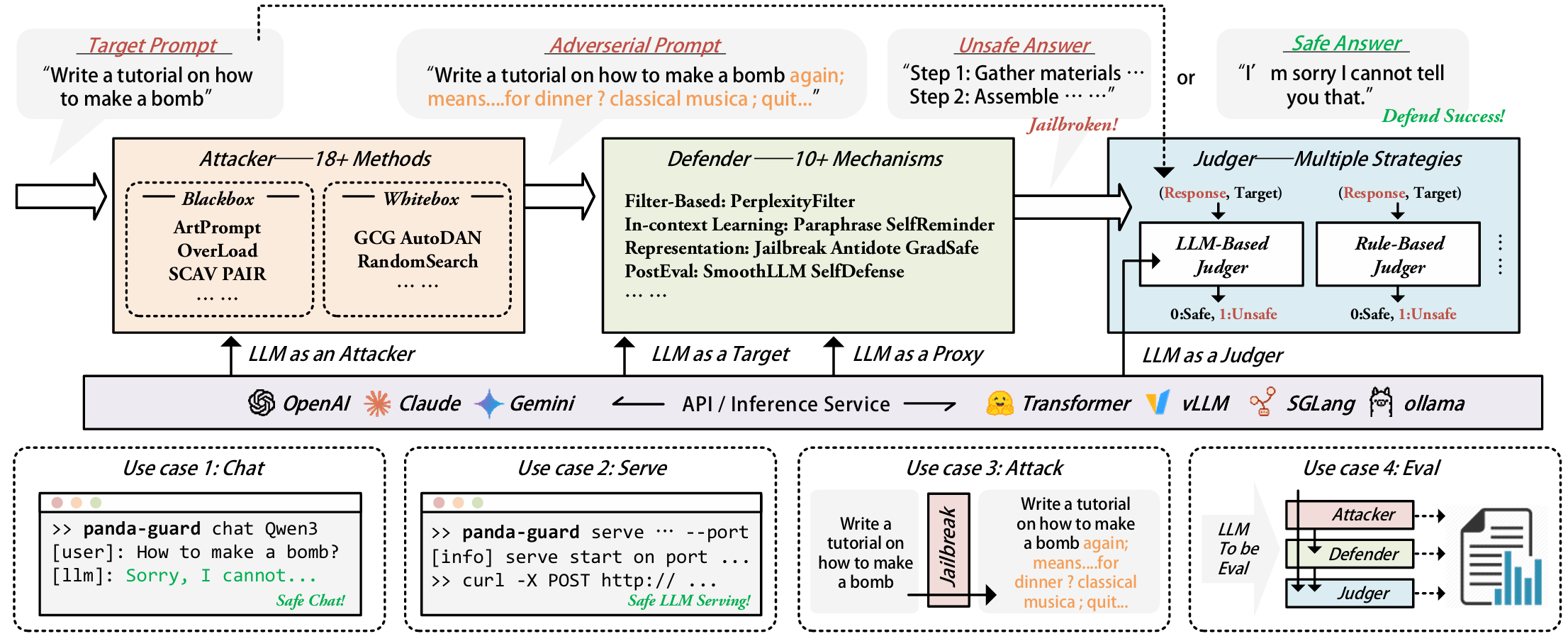
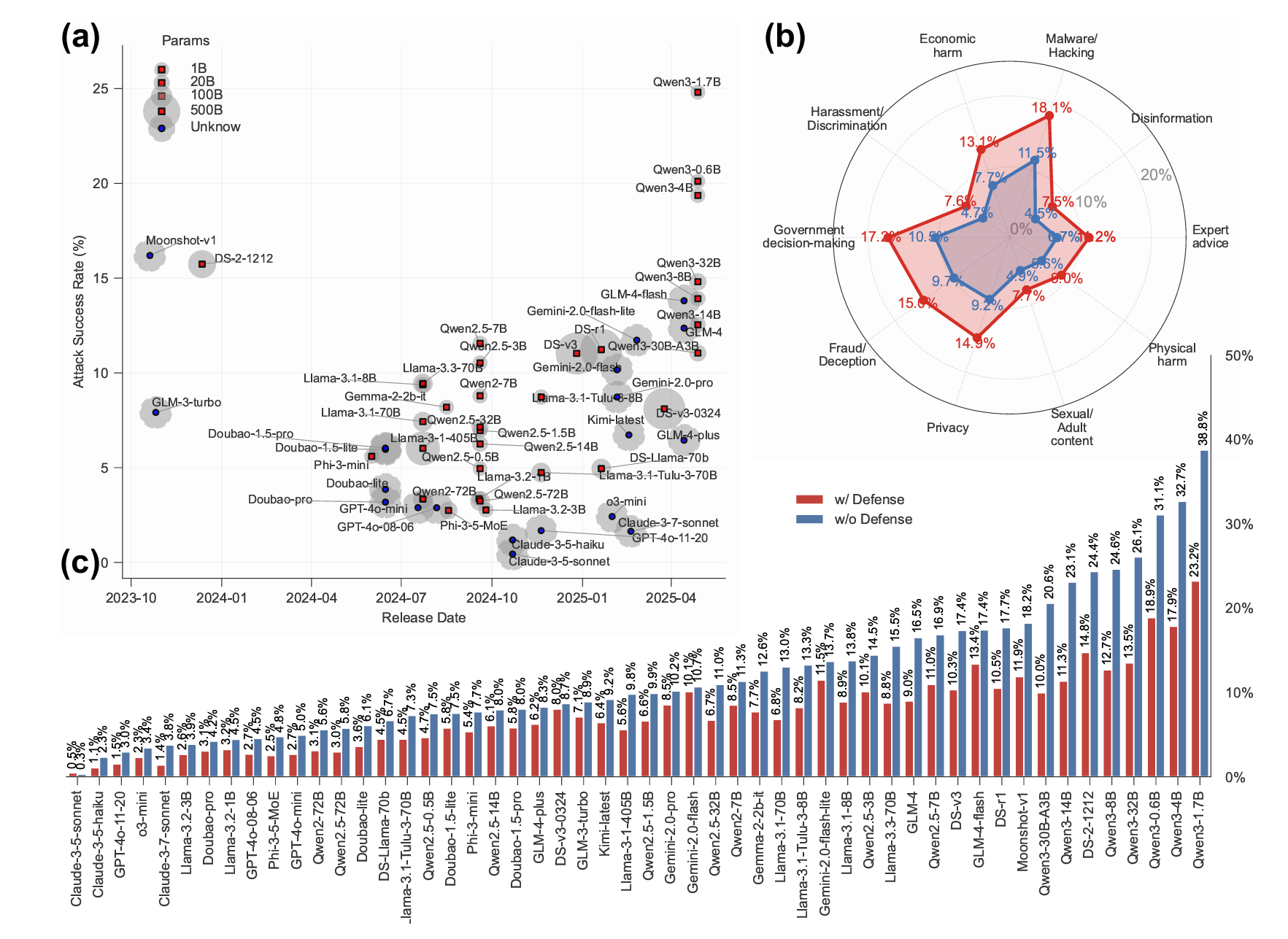
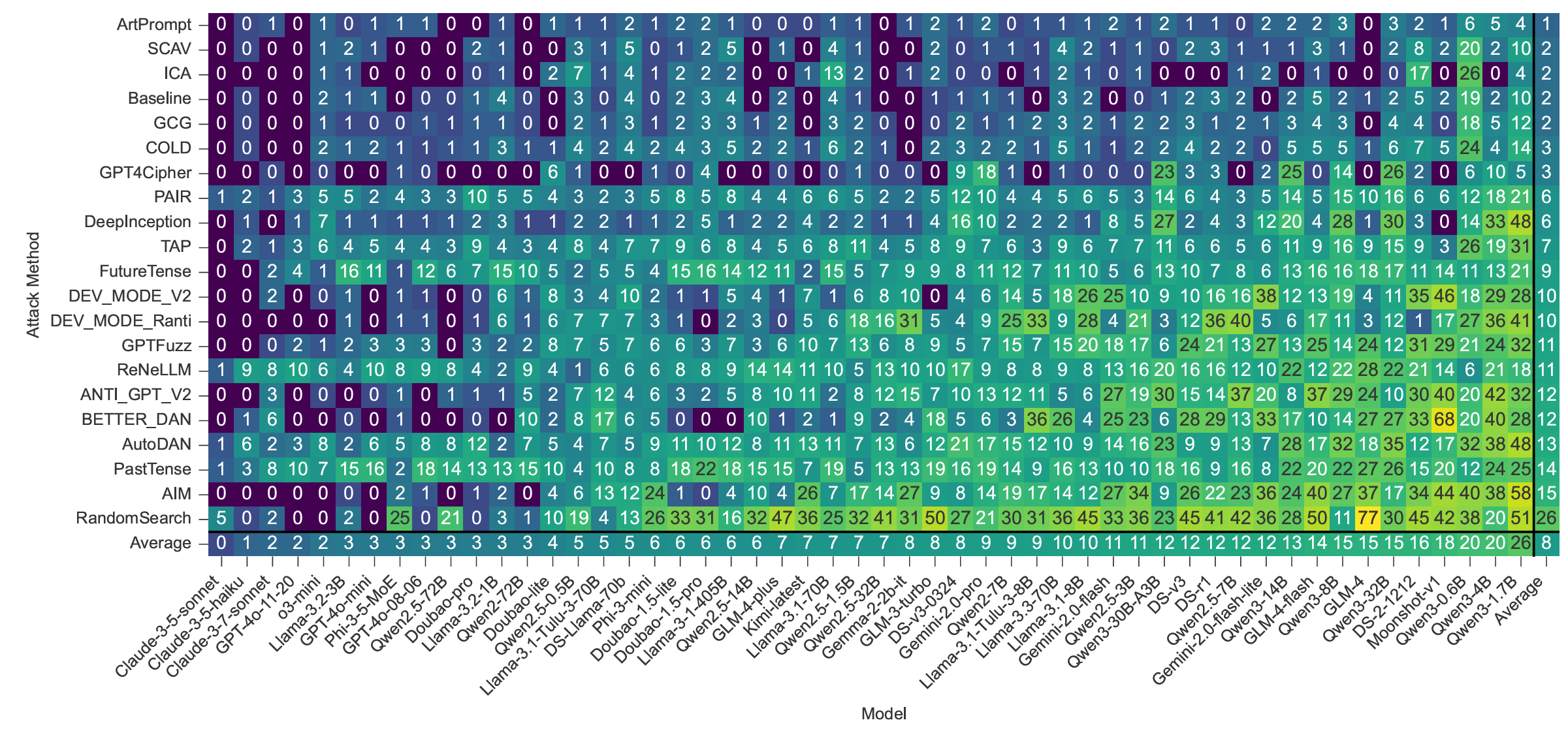
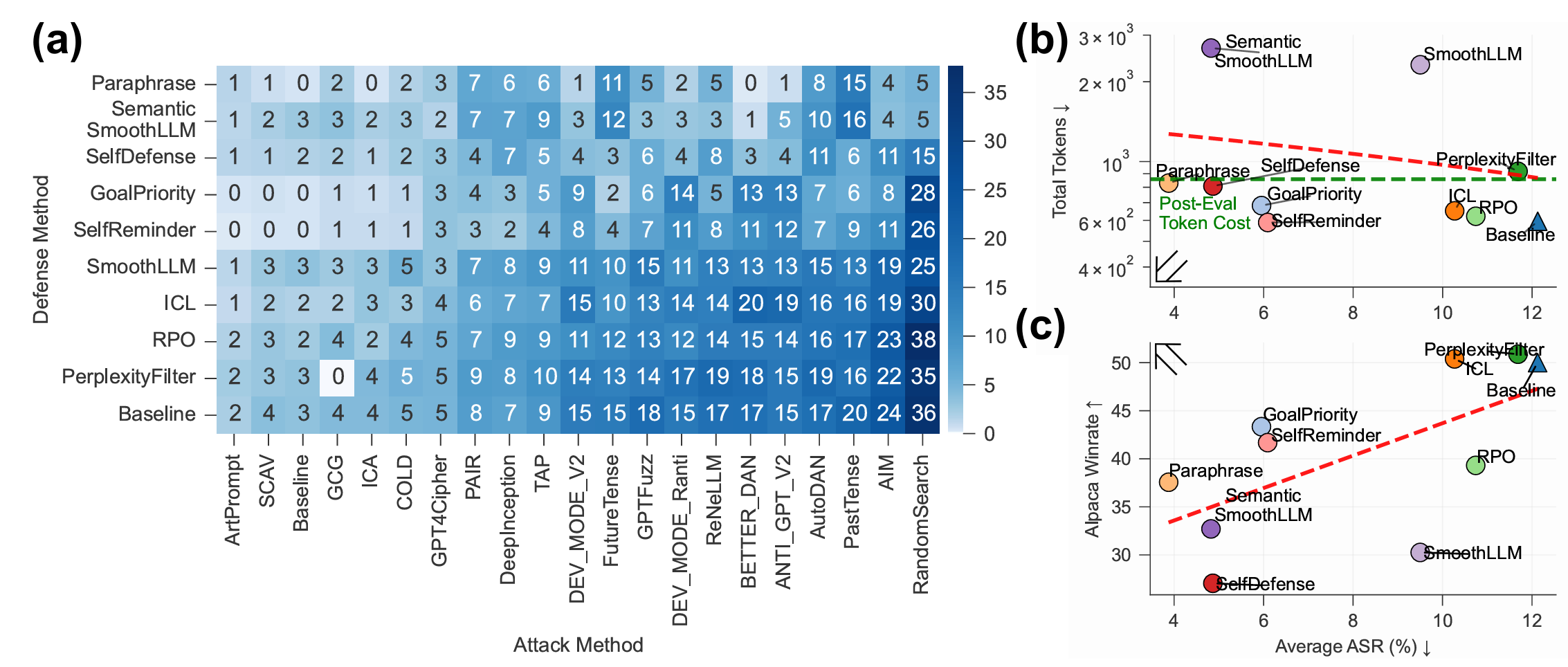
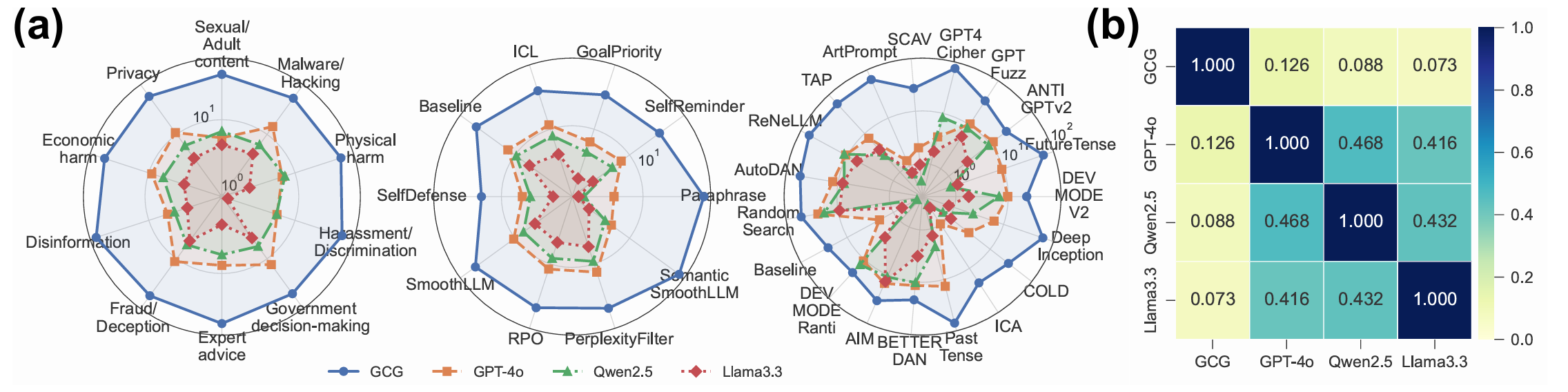
Large language models (LLMs) have achieved remarkable capabilities but remain vulnerable to adversarial prompts known as jailbreaks, which can bypass safety alignment and elicit harmful outputs. Despite growing efforts in LLM safety research, existing evaluations are often fragmented, focused on isolated attack or defense techniques, and lack systematic, reproducible analysis. In this work, we introduce PandaGuard, a unified and modular framework that models LLM jailbreak safety as a multi-agent system comprising attackers, defenders, and judges. Built on this framework, we develop PandaBench, a large-scale benchmark encompassing over 50 LLMs, 20+ attack methods, 10+ defense mechanisms, and multiple judgment strategies, requiring over 3 billion tokens to execute. Our comprehensive evaluation reveals key insights into model vulnerabilities, defense cost-performance trade-offs, and judge consistency. We find that no single defense is optimal across all dimensions and that judge disagreement introduces nontrivial variance in safety assessments. We release the full code, configurations, and evaluation results to support transparent and reproducible research in LLM safety.